- Услуги и решения
СДУ «Приоритет» Платформа Communigate Pro Платформа ЦРП Долговременный электронный архив Обработка обращений граждан Мобильный клиент к СЭД Разработка приложений
под ОС «Аврора» ЕИР Диспансеризация Защищенная мобильность 2.0СЭД Docsvision СДУ «Приоритет» Электронный архив Поддержка бизнес-процессов Конфиденциальный документооборот Обработка внутренних заявок Автоматизация юридической службы Автоматизация кадрового документооборота СЭД DV Box Автоматизация системы менеджмента качестваЦентр информационной безопасности Аттестация информационных систем Цифровой КУПОЛ Защита объектов КИИ Защита АСУ ТП Категорирование объектов КИИ Управление идентификационными данными (IDM) Управление информационной безопасностью (SIEM) Защищенная мобильность 2.0 Защищенный документооборот Центр мониторинга и реагирования на инциденты (SOC)АРМ обходчика Технический архив Защита АСУ ТП Расчет энергетических режимов ГЭС Система сводного планирования Автоматизация проведения
инструктажей сотрудников Учет жизненного цикла
ламп для теплицыПлатформа Communigate Pro Управление идентификационными данными (IDM) Система обработки журналов событий «Логрус»Система «Ареопад» АРМ обходчика Защищенная мобильность 2.0 Мобильный клиент к СЭД Разработка приложений
под ОС «Аврора»Разработка корпоративных порталов Поддержка решений на SharePoint Разработка на Битрикс Портал работы с поставщиками Платформа «Цифровое рабочее пространство»Автоматизация закупок Обработка внутренних заявок Автоматизация системы менеджмента качества Автоматизация кадрового документооборота Автоматизация юридической службыАвтоматизация внутреннего аудита, контроля и оценки рисков (АВАКОР) Автоматизация внутреннего аудита Автоматизация управления рисками АВАКОР. Инсайт - искусственный интеллект в корпоративном контроле Автоматизация внутреннего контроля Автоматизация комплаенс-контроля Внутренний контроль в целях налогового мониторингаСвяжитесь с нами, и мы поможем подобрать оптимальное решение для ваших задач Связаться - Проекты
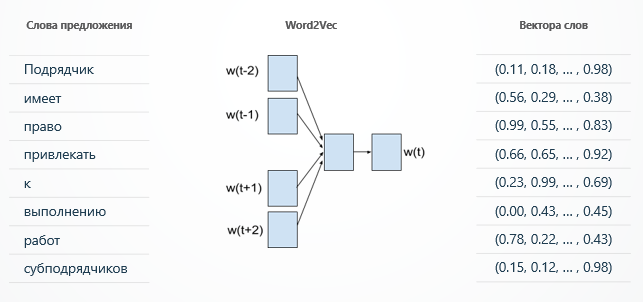
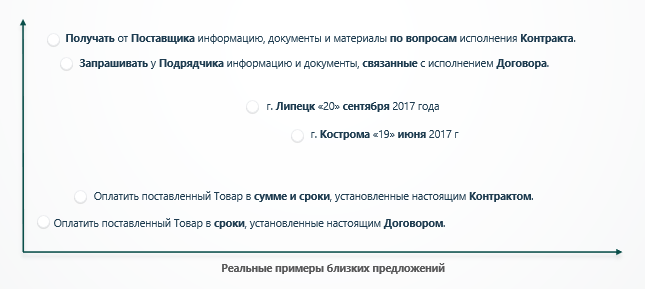
- Научная лаборатория
- О компании
- Карьера